Parallel computing
Before starting, be advised that this chapter is in continuous work-in-progress mode, which translates into potential changes in the ordering of the sections, availability of contents, etc.
Introduction
In this chapter we will introduce the reader to parallel computing using R. In particular, we will take a general overview of what is parallel computing, how can it benefit us, and how can it be used in R.
The rest of this chapter develops under the assumption that the reader has some level of knowledge about R fundamentals (types of objects, functions, etc.).
What is parallel computing, anyway?
In very simple terms, parallel computing is all about making things run faster. More concrete, while there are plenty of ways of accelerating calculations, parallel computing is all about doing multiple things simultaneously.
Sequential computing, on the other hand, is what we usually see in R. When we make a call to a function, most of the time R is doing calculations using a single processor. While this may not be a problem if your call takes just a couple of seconds, it may be critical if, for example, the program needs to make a significant number of such calls, say 1,000, in order to be completed.
While not a general rule, most of the time computationally intensive programs can be split in such a way that its components can be executed in an isolated way, this is, without relying on the other parts to be completed.
For example, suppose that you have a function that takes a number and multiplies it by 2, let’s call it f:
In R, this simple function can be applied seamlessly to a vector, for example:
## [1] 2 4 6 8If we were able to see how calculations are taking place in R, we could represent this in the following way:
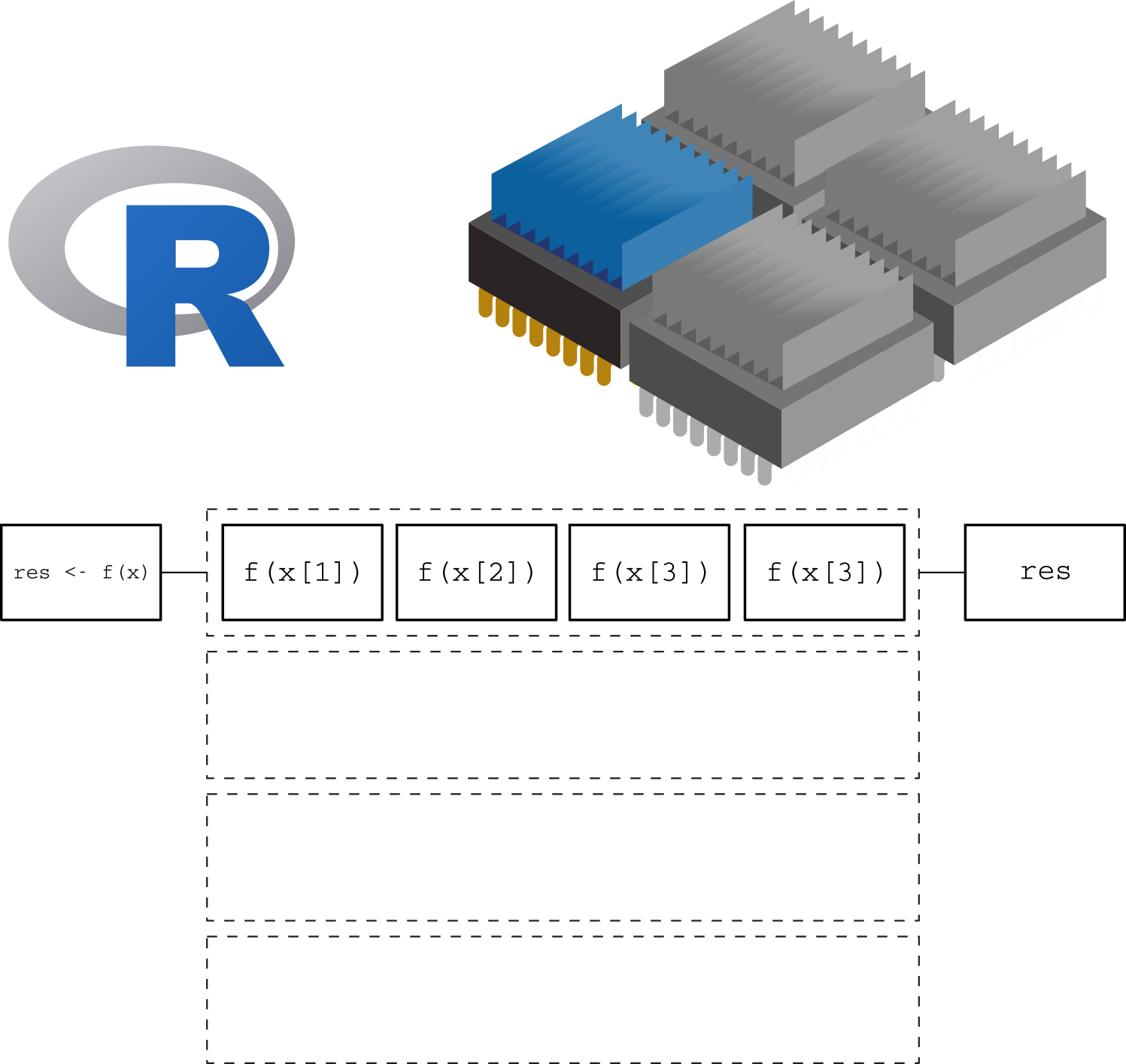
Here we are using a single core. The function is applied one element at a time, leaving the other 3 cores without usage.
Now, in a parallel computing setting, the same function can be applied simultaneously to multiple elements of x, as in the following figure, where the number of cores matches the number of elements/tasks that need to be processed:
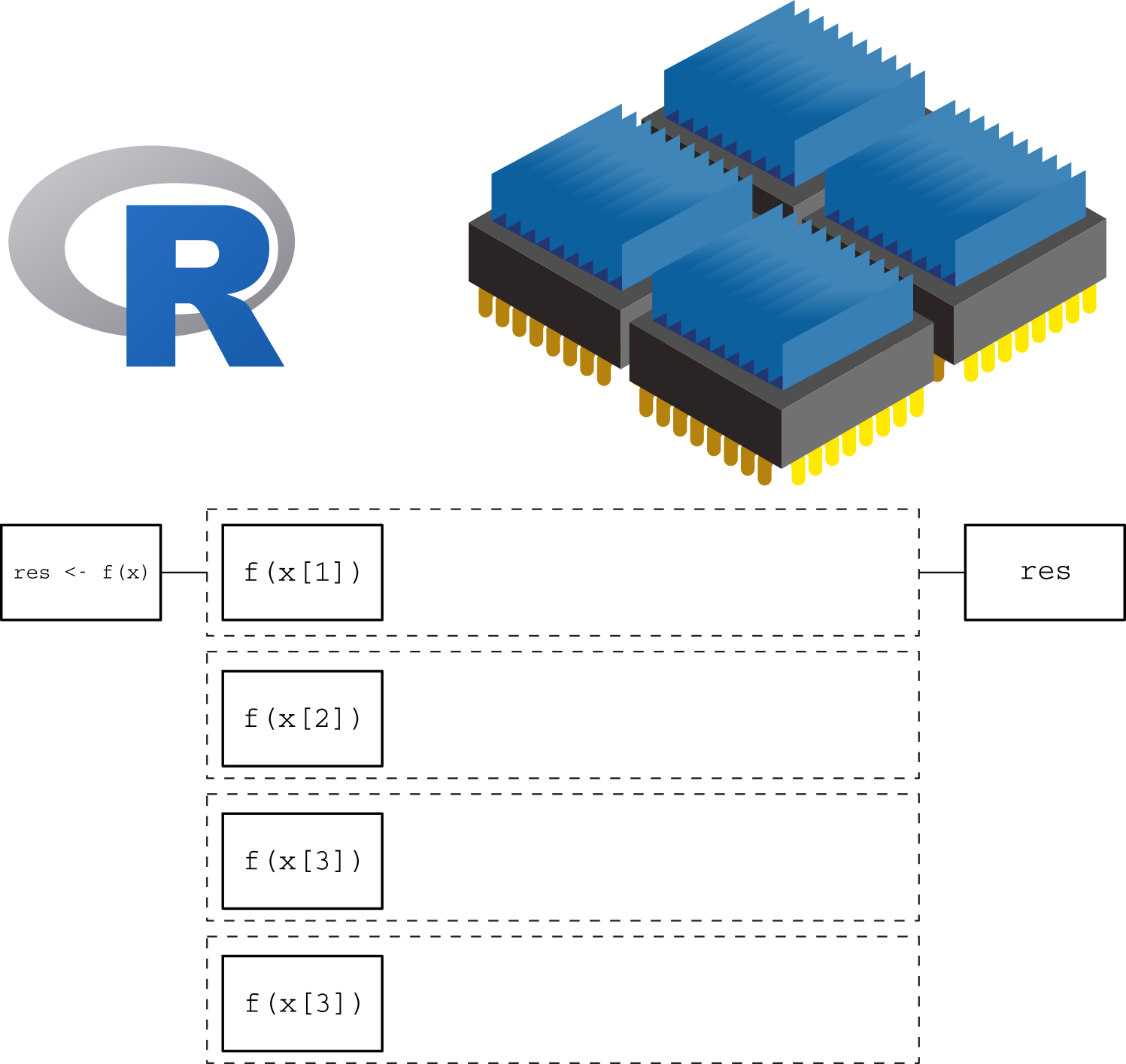
In this more intelligent way of computation, we are taking full advantage of our computer by using all 4 cores at the same time. This will translate in a reduced computation time which, in the case of complicated/long calculations, can be an important speed gain.
In principle, this implementation of the function f should take 1/4 of what the original version takes to be applied to x. As the number of function calls increases, or in other words, as the complexity in terms of computational time increases, it makes sense to start thinking about parallel computing. This takes us to the next section.
When is it a good idea?
Parallel computing sounds great, but is it always a good idea to try to parallelize your program? The answer is no.
A lot of times we feel pushed towards writing the code as efficiently as possible. Moreover, this is a known problem among software developers, see for example this hilarious reply on Stackoverflow regarding “best comment in source code”1:
//
// Dear maintainer:
//
// Once you are done trying to 'optimize' this routine,
// and have realized what a terrible mistake that was,
// please increment the following counter as a warning
// to the next guy:
//
// total_hours_wasted_here = 42
// While optimizing a program may be important in some cases, time constraints and readability may be more important in relative terms. As a rule of thumb, you will only want to optimize your code if by doing so the potential speed gains are worthwhile, for example, reducing computation speed to half of the original time in an algorithm that takes more than just a few seconds. Other examples include:
A good idea when:
You are writing a log-likelihood Function that you need to maximize. Solvers take, for example, at least 5 calls to the objective function so it makes sense to speed up the call.
Even more relevant than a simple optimization, if the function needs to be called thousands of times like in an MCMC algorithm, then it definitely makes sense to improve speed.
You are processing chunks of data in which each requires a significant amount of time to be processed.
Bad idea when:
The section of the program that you want to speed up already takes a relatively small time to be completed, for example, a few seconds or a fraction of a second.
The section of the program you are trying to optimize is not the actual bottleneck of the program2
If your computational problem is reasonable enough to think about code optimization, and furthermore, implementing parallel computing, then the following diagram should be a useful guide to follow:
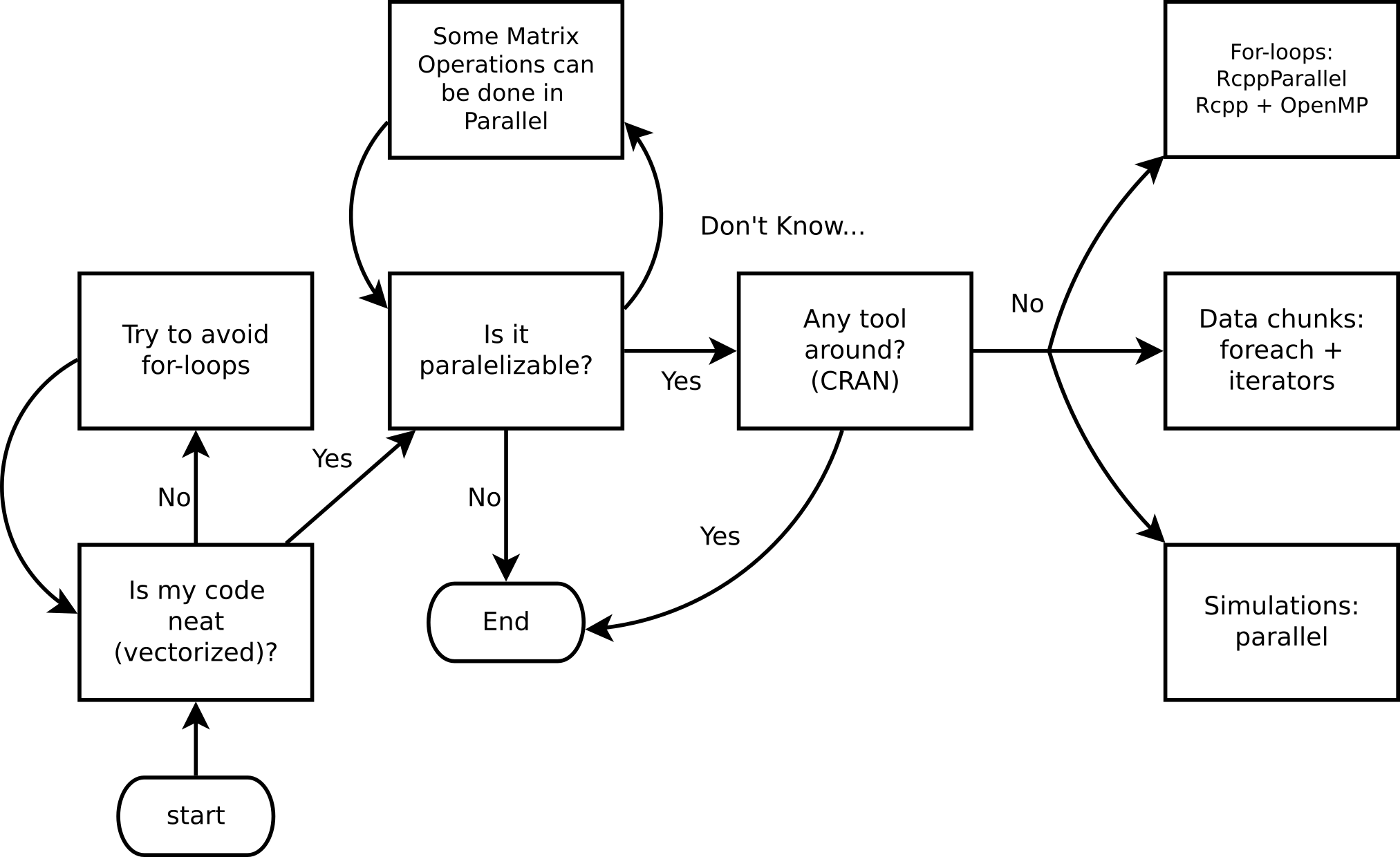
Ask yourself these questions before jumping into HPC!
If your problem reached the part in which it can be parallelized but there are no tools around for you to use, keep reading, otherwise move to the next chapter, and don’t come back until you have a problem worthy enough to be dealt with parallel computing… just kidding.
Fundamentals
Before jumping into HPC with R, let’s take a look at some concepts that are fundamental for the rest of the chapter.
Types of parallelisms
A nice way to look at types of computation is through Flynn’s taxonomy:
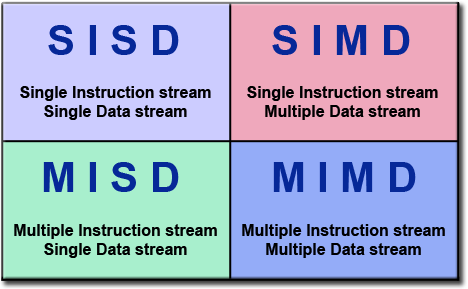
Flynn’s Classical Taxonomy. Source: Introduction to Parallel Computing, Blaise Barney, Lawrence Livermore National Laboratory (website)
What you need to know about Hardware
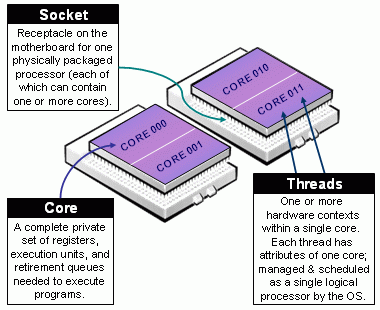
One important thing to know is how many resources we have, and resources can be very different across systems. In general, we can talk about a computer’s processing unit, CPU, as a collection of cores which are grouped/arranged in sockets. Moreover, modern CPUs such as those built by intel have what they call multithreaded technology, which in raw terms means a single physical core behaving as multiple ones. The following figure shows a nice illustration of this:
Taxonomy of CPUs (Downloaded from de https://slurm.schedmd.com/mc_support.html)
Now, how many cores does your computer has, the parallel package can tell you that:
## [1] 12HPC in R
Loosely, from R’s perspective, we can think of HPC in terms of two, maybe three things:
Big data: How to work with data that doesn’t fit your computer
Parallel computing: How to take advantage of multiple core systems
Compiled code: Write your own low-level code (if R doesn’t have it yet…)
In the case of Big Data, some solutions include:
Buy a bigger computer/RAM memory (not the best solution!)
Use out-of-memory storage, i.e., don’t load all your data in the RAM. e.g. The bigmemory, data.table, HadoopStreaming R packages
Store it more efficiently, e.g.: Sparse Matrices (take a look at the
dgCMatrixobjects from the Matrix R package)
Parallel computing in R
As mentioned earlier, R was not designed to work with parallel computing out-of-the-box. While there are some ways to go around this such as:
Obtaining the R version owned by Microsoft (Microsoft R Open), which has some features, and in particular, linear algebra routines compiled in parallel;
Compiling R with BLAS allowing for parallel computing (a couple of examples here and here);
Getting the opensource version pqR (pretty quick R, which at the writing of this has a stable release published on February 19th, 2019);
When it comes to using “normal” R, there are several alternatives (just take a look at the High-Performance Computing Task View).
When you have a task that you need to perform in parallel it comes in two main flavors. The first flavor is what we call embarrassingly parallel or perfectly parallel. These are tasks where you need to do one thing many many times over with complete independence between each task. Wrapping 100 presents is a perfectly parallel task. Inviting 4 friends over would make that task almost 5 times faster then if you were to do that task yourself. The second flavor is one massive task that has some sub-parts that could use parallel computing tasks. These tasks often involve iterative tasks and matrix multiplications
here are examples of how to use different packages to speed up embarrassingly parallel tasks.
We will showcase how to perform these tasks using the same task.
Simulating pi
We know that \(\pi = \frac{A}{r^2}\). We approximate it by randomly adding points \(x\) to a square of size 2 centered at the origin.
So, we approximate \(\pi\) as \(\Pr\{\|x\| \leq 1\}\times 2^2\)
The R code to do this
pisim <- function(nsim) {
ans <- matrix(runif(nsim * 2), ncol = 2)
ans <- sqrt(rowSums(ans ^ 2))
(sum(ans <= 1) * 4) / nsim
}
pisim(1000)## [1] 3.164The non-parallel way to run this many times is to use a looping structure such as lapply(), vapply() or purrr::map().
## [[1]]
## [1] 4
##
## [[2]]
## [1] 4
##
## [[3]]
## [1] 2.666667
##
## [[4]]
## [1] 4
##
## [[5]]
## [1] 3.2## [1] 4.0 4.0 4.0 2.0 3.2## [[1]]
## [1] 0
##
## [[2]]
## [1] 4
##
## [[3]]
## [1] 4
##
## [[4]]
## [1] 4
##
## [[5]]
## [1] 3.2## [1] 0.0 4.0 4.0 2.0 3.2Embarresinly parallel
The future.apply package
The future.apply package is a small package based on the future package to allow for a drop-in replacement for *apply() functions.
If your code has a place where you are using any of the *apply() functions you can simply specify a plan and prefix the applys with future_
## Loading required package: future## [[1]]
## [1] 0
##
## [[2]]
## [1] 4
##
## [[3]]
## [1] 2.666667
##
## [[4]]
## [1] 3
##
## [[5]]
## [1] 3.2## [1] 4.000000 4.000000 2.666667 4.000000 2.400000The furrr package
The furrr package is a small package based on the future package to allow for a drop-in replacement for purrr’s map() functions.
If your code has a place where you are using any of the purrr::map*() functions you can simply specify a plan and prefix the applys with future_
## [[1]]
## [1] 0
##
## [[2]]
## [1] 4
##
## [[3]]
## [1] 4
##
## [[4]]
## [1] 4
##
## [[5]]
## [1] 3.2## [[1]]
## [1] 4
##
## [[2]]
## [1] 2
##
## [[3]]
## [1] 4
##
## [[4]]
## [1] 4
##
## [[5]]
## [1] 3.2The foreach
The foreach package provides a nice looping structure. You start with a call to foreach() where you pass what you want to loop over then %do% into an expression you want to be performed.
In this case, have we passed in the vector 1:5 and it is passed to pisim().
## [[1]]
## [1] 0
##
## [[2]]
## [1] 4
##
## [[3]]
## [1] 4
##
## [[4]]
## [1] 4
##
## [[5]]
## [1] 4if you want to perform the same function multiple times you simply pass foreach a vector with a length of the desired number of iterations. This is easily done with seq_len()
## [[1]]
## [1] 3.1044
##
## [[2]]
## [1] 3.1588
##
## [[3]]
## [1] 3.1376
##
## [[4]]
## [1] 3.1296
##
## [[5]]
## [1] 3.1524foreach() comes with a .combine argument which specifies how the result from each iteration should be combined. c() works well for concatenating vectors
## [1] 4.0 4.0 4.0 4.0 3.2but you can also use functions like rbind() if your output is a data.frame and want them combined. (This example is not a very efficient, but it illustrates a broader use-case)
## pi
## 1 0.000000
## 2 4.000000
## 3 2.666667
## 4 4.000000
## 5 3.200000The parallel package
parallel: R package that provides ‘[s]upport for parallel computation, including random-number generation’.
Create a cluster:
PSOCK Cluster:
makePSOCKCluster: Creates brand new R Sessions (so nothing is inherited from the master), even in other computers!Fork Cluster:
makeForkCluster: Using OS Forking, copies the current R session locally (so everything is inherited from the master up to that point). Not available on Windows.Other:
makeClusterpassed to snow
Copy/prepare each R session:
Copy objects with
clusterExportPass expressions with
clusterEvalQSet a seed
Do your call:
mclapply,mcmapplyif you are using ForkparApply,parLapply, etc. if you are using PSOCK
Stop the cluster with
clusterStop
parallel example 1: Simulating \(\pi\)
To be able to use a function in the parallel framework we need to do a small rewrite of the function such that it starts with an i argument.
parallel_pisim <- function(i, nsim) {
ans <- matrix(runif(nsim * 2), ncol = 2)
ans <- sqrt(rowSums(ans ^ 2))
(sum(ans <= 1) * 4) / nsim
}
# 1. CREATING A CLUSTER
library(parallel)
cl <- makePSOCKcluster(10)
# 2. PREPARING THE CLUSTER
clusterSetRNGStream(cl, 123)
# Number of simulations we want each time to run
nsim <- 1e5
# We need to make -nsim- and -pisim- available to the
# cluster
clusterExport(cl, c("nsim", "parallel_pisim"))
# 3. DO YOUR CALL
parLapply(cl, 1:5, parallel_pisim, nsim = nsim)## [[1]]
## [1] 3.14696
##
## [[2]]
## [1] 3.1378
##
## [[3]]
## [1] 3.14236
##
## [[4]]
## [1] 3.14052
##
## [[5]]
## [1] 3.13144## [1] 3.14420 3.14276 3.13592 3.14480 3.14628Please note that parallel does have a parVapply() so you need to be really careful with your output.
parallel example 2: Parallel RNG
# 1. CREATING A CLUSTER
cl <- makePSOCKcluster(2)
# 2. PREPARING THE CLUSTER
clusterSetRNGStream(cl, 123) # Equivalent to `set.seed(123)`
# 3. DO YOUR CALL
ans <- parSapply(cl, 1:2, function(x) runif(1e3))
(ans0 <- var(ans))## [,1] [,2]
## [1,] 0.0861888293 -0.0001633431
## [2,] -0.0001633431 0.0853841838# I want to get the same!
clusterSetRNGStream(cl, 123)
ans1 <- var(parSapply(cl, 1:2, function(x) runif(1e3)))
ans0 - ans1 # A matrix of zeros## [,1] [,2]
## [1,] 0 0
## [2,] 0 0In the case of makeForkCluster
# 1. CREATING A CLUSTER
library(parallel)
# The fork cluster will copy the -nsims- object
nsims <- 1e3
cl <- makeForkCluster(2)
# 2. PREPARING THE CLUSTER
RNGkind("L'Ecuyer-CMRG")
set.seed(123)
# 3. DO YOUR CALL
ans <- do.call(cbind, mclapply(1:2, function(x) {
runif(nsims) # Look! we use the nsims object!
# This would have failed in makePSOCKCluster
# if we didn't copy -nsims- first.
}))
(ans0 <- var(ans))## [,1] [,2]
## [1,] 0.08538418 0.00239079
## [2,] 0.00239079 0.08114219# Same sequence with same seed
set.seed(123)
ans1 <- var(do.call(cbind, mclapply(1:2, function(x) runif(nsims))))
ans0 - ans1 # A matrix of zeros## [,1] [,2]
## [1,] 0 0
## [2,] 0 0Allowing parallel computing in your R package
If you are writing a package that has functions that perform tasks that are done in parallel it is advised that you use foreach or future in your package. This will mean that you as the package author can decide what parts of your code can run in parallel, and the user can decide how it should be run.