
![]()

![]()
![]()
What
The fmcmc R package provides a lightweight general framework for implementing Markov Chain Monte Carlo methods based on the Metropolis-Hastings algorithm. This implementation’s primary purpose lies in the fact that the user can incorporate the following flexibly:
Automatic convergence checker: The algorithm splits the MCMC runs according to the frequency with which it needs to check convergence. Users can use either one of the included functions (
convergence_gelman,convergence_geweke,etc.), or provide their own.Run multiple chains in parallel fashion: Using either a
PSOCKcluster (default), or providing a personalized cluster object like the ones in theparallelR package.User defined transition kernels: Besides of canonical Gaussian Kernel, users can specify their own or use one of the included in the package, for example:
kernel_adapt,kernel_ram,kernel_normal_reflective,kernel_unif,kernel_mirror, orkernel_unif_reflective.
All the above without requiring compiled code. For the latest about fmcmc, checkout the NEWS.md section.
Who is this for?
While a lot of users rely on MCMC tools such as Stan (via the rstan package) or WinBUGS (via rstan), in several settings either these tools are not enough or provide too much for things that do not need that much. So, this tool is for you if:
You have a simple model to estimate with Metropolis-Hastings.
You want to run multiple chains of your model using out-of-the-box parallel computing.
You don’t want (or cannot) rely on external tools (so you need good-old base R only for your models).
You want to implement a model in which your model parameters are either bounded (like a standard error, for example), or are not, say, continuous (e.g., a size variable in a Binomial distribution), so you need a personalized transition kernel.
In any other case, you may want to take a look at the previously mentioned R packages, or check out the mcmc R package, which also implements the Metropolis-Hastings algorithm (although with not all the features that this R package has), the adaptMCMC R package, or the MCMCpack R package.
Installing
If you want to get the latest bleeding-edge version from Github, you can use devtools:
devtools::install_github("USCbiostats/fmcmc")The latest (stable) release is also available on CRAN:
install.packages("fmcmc")Citation
To cite fmcmc in publications use:
Vega Yon et al., (2019). fmcmc: A friendly MCMC framework. Journal of
Open Source Software, 4(39), 1427,
https://doi.org/10.21105/joss.01427
And the actual R package:
Vega Yon G, Marjoram P (2025). _fmcmc: A friendly MCMC framework_.
doi:10.32614/CRAN.package.fmcmc
<https://doi.org/10.32614/CRAN.package.fmcmc>, R package version
0.6-0, <https://cran.r-project.org/package=fmcmc>.
To see these entries in BibTeX format, use 'print(<citation>,
bibtex=TRUE)', 'toBibtex(.)', or set
'options(citation.bibtex.max=999)'.Example: Linear regression model
First run
In the following we show how to use the package for estimating parameters in a linear regression model. First, let’s simulate some data to use:
In this case, we have three parameters to estimate, the constant (2.0), the coefficient (2.0), and the standard deviation parameter of the error (1.5).
To estimate this model, we can either maximize the log-likelihood function–which is what is usually done–or we could do it using MCMC. In either case, we need to specify the log(unnormalized some times)-likelihood function:
ll <- function(p, X., y.) {
joint_ll <- dnorm(y. - (p[1] + X.*p[2]), sd = p[3], log = TRUE)
joint_ll <- sum(joint_ll)
# If is undefined, then we explicitly return infinte (instead of NaN, for
# example)
if (!is.finite(joint_ll))
return(-Inf)
joint_ll
}Notice that the function has more than one argument, in this case, p, the vector of parameters, X. and y., the data of our model.
Let’s do a first run of the MCMC algorithm using the function of the same name (first, load the package, of course):
Thank you for using fmcmc! Please consider citing it in your work.
You can find the citation information by running
citation("fmcmc")
# Running the MCMC (we set the seed first)
set.seed(1215)
ans <- MCMC(
ll,
initial = c(0, 0, sd(y)),
nsteps = 5000,
X. = X,
y. = y
)As the output object is an object of class mcmc from the coda R package, we can use all the functions from it on our output:
summary(ans)Iterations = 1:5000
Thinning interval = 1
Number of chains = 1
Sample size per chain = 5000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
par1 3.113 0.17593 0.002488 0.024341
par2 1.975 0.10647 0.001506 0.022105
par3 4.093 0.07843 0.001109 0.005951
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
par1 2.975 3.029 3.068 3.255 3.354
par2 1.749 1.907 1.980 2.020 2.145
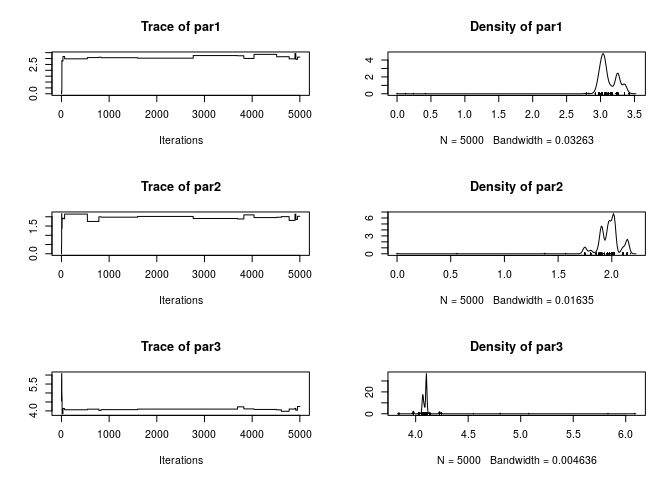
par3 3.978 4.070 4.101 4.102 4.226While the summary statistics look very good (we got very close to the original parameters), the trace of the parameters looks very bad (poor mixing). We can re-run the algorithm changing the scale parameter in the kernel_normal function. To do so, we can pass ans as the initial argument so that the function starts from the last point of that chain:
ans <- MCMC(
ll,
initial = ans,
nsteps = 5000,
X. = X,
y. = y,
kernel = kernel_normal(scale = .05) # We can set the scale parameter like this
)
plot(ans)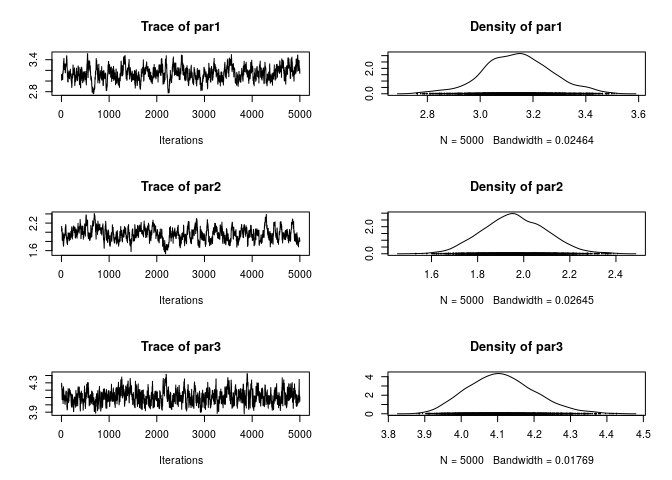
Much better! Now, what if we use Vihola (2012) Robust Adaptive Metropolis (which is also implemented in the R package adaptMCMC)
ans_RAM <- MCMC(
ll,
initial = ans,
nsteps = 5000,
X. = X,
y. = y,
kernel = kernel_ram()
)
plot(ans_RAM)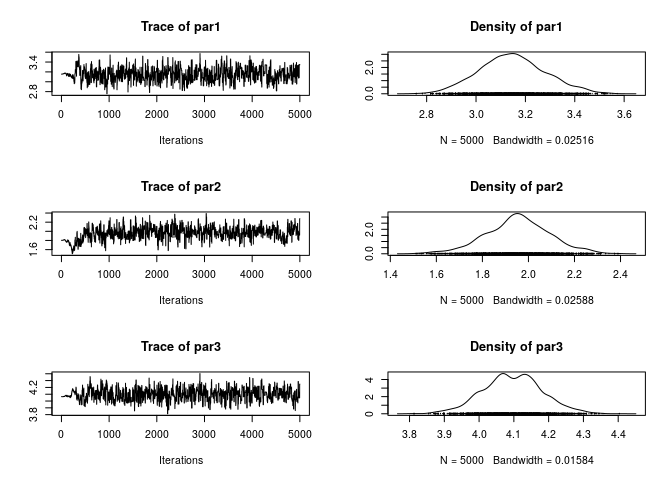
1 - rejectionRate(ans_RAM)We can also try using Haario et al. (2001) Adaptive Metropolis
ans_AM <- MCMC(
ll,
initial = ans,
nsteps = 5000,
X. = X,
y. = y,
kernel = kernel_adapt()
)
plot(ans_AM)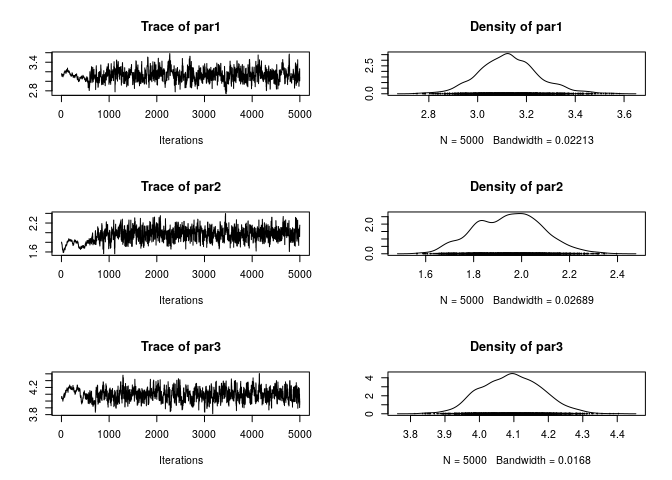
1 - rejectionRate(ans_AM)Finally, if needed, we can also access information about the last run using MCMC_OUTPUT. For example, if we wanted to look at the trace of the logposterior function, we could use the get_logpost() function:
plot(get_logpost(), type = "l")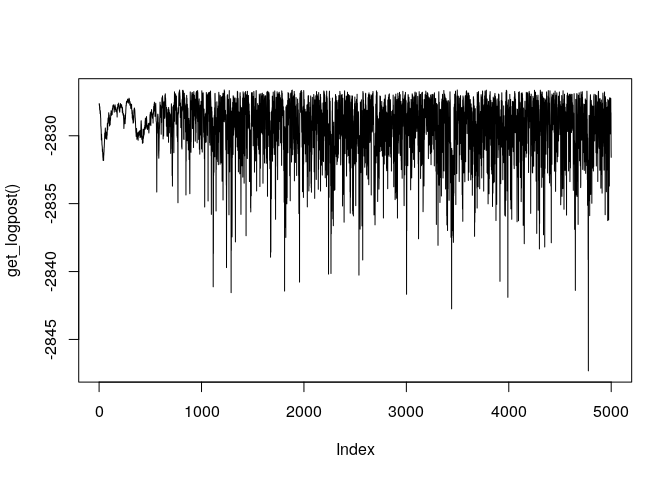
The set of proposed values is also available using the get_draws() function:
If the previous run featured multiple chains, then get_logpost() would return a list instead of length get_nchains().
Automatic stop
Now, suppose that the algorithm actually takes a lot of time to actually reach stationary state, then it would be nice to actually sample from the posterior distribution once convergence has been reached. In the following example we use multiple chains and the Gelman-Rubin diagnostic to check for convergence of the chain:
set.seed(1215) # Same seed as before
ans <- MCMC(
ll,
initial = c(0, 0, sd(y)),
nsteps = 5000,
X. = X,
y. = y,
kernel = kernel_normal(scale = .05),
nchains = 2, # Multiple chains
conv_checker = convergence_gelman(200) # Checking for conv. every 200 steps
)No convergence yet (steps count: 200). Gelman-Rubin's R: 4.5843. Trying with the next bulk.
No convergence yet (steps count: 400). Gelman-Rubin's R: 1.1877. Trying with the next bulk.
No convergence yet (steps count: 600). Gelman-Rubin's R: 1.4297. Trying with the next bulk.
No convergence yet (steps count: 800). Gelman-Rubin's R: 1.1582. Trying with the next bulk.
No convergence yet (steps count: 1000). Gelman-Rubin's R: 1.3414. Trying with the next bulk.
No convergence yet (steps count: 1200). Gelman-Rubin's R: 1.2727. Trying with the next bulk.
No convergence yet (steps count: 1400). Gelman-Rubin's R: 1.4456. Trying with the next bulk.
No convergence yet (steps count: 1600). Gelman-Rubin's R: 1.3792. Trying with the next bulk.
No convergence yet (steps count: 1800). Gelman-Rubin's R: 1.2069. Trying with the next bulk.
No convergence yet (steps count: 2000). Gelman-Rubin's R: 1.1789. Trying with the next bulk.
No convergence yet (steps count: 2200). Gelman-Rubin's R: 1.1208. Trying with the next bulk.
No convergence yet (steps count: 2400). Gelman-Rubin's R: 1.1196. Trying with the next bulk.
Convergence has been reached with 2600 steps. Gelman-Rubin's R: 1.0792. (2600 final count of samples).As a difference from the previous case, now we didn’t have to wait until the 5,000 completed, but the algorithm stopped for us, allowing us to start generating the desired sample much quicker.
Kernels: Making sure that we get positive values
For this final example, we will use the kernel argument and provide what corresponds to a transition kernel which makes proposals within certain boundaries, in particular, we want the algorithm to propose only positive values for the sd parameter, which we now must be positive.
Moreover, since we know that we will only get positive values, we can go further and modify ll skipping the check for finite values:
Much simpler function! Let’s do the call of the MCMC function specifying the right transition kernel to increase the acceptance rate. In this example, we will set the max of all parameters to be 5.0, and the min to be -5.0 for the constant and 0 for the beta coefficient and the variance parameter, all this using the kernel_normal_reflective (which implements a normal kernel with boundaries) function:
set.seed(1215) # Same seed as before
ans <- MCMC(
ll,
initial = c(0, 0, sd(y)),
nsteps = 5000,
X. = X,
y. = y,
kernel = kernel_normal_reflective(
ub = 5.0, # All parameters have the same upper bound
lb = c(-5.0, 0.0, 0.0), # But lower bound is specified per parameter
scale = 0.05 # This is the same scale as before
),
nchains = 2,
conv_checker = convergence_gelman(200)
)No convergence yet (steps count: 200). Gelman-Rubin's R: 3.7891. Trying with the next bulk.
No convergence yet (steps count: 400). Gelman-Rubin's R: 1.1257. Trying with the next bulk.
No convergence yet (steps count: 600). Gelman-Rubin's R: 1.4696. Trying with the next bulk.
No convergence yet (steps count: 800). Gelman-Rubin's R: 1.1313. Trying with the next bulk.
No convergence yet (steps count: 1000). Gelman-Rubin's R: 1.4384. Trying with the next bulk.
No convergence yet (steps count: 1200). Gelman-Rubin's R: 1.3696. Trying with the next bulk.
No convergence yet (steps count: 1400). Gelman-Rubin's R: 1.5243. Trying with the next bulk.
No convergence yet (steps count: 1600). Gelman-Rubin's R: 1.3720. Trying with the next bulk.
No convergence yet (steps count: 1800). Gelman-Rubin's R: 1.1722. Trying with the next bulk.
No convergence yet (steps count: 2000). Gelman-Rubin's R: 1.1492. Trying with the next bulk.
No convergence yet (steps count: 2200). Gelman-Rubin's R: 1.1004. Trying with the next bulk.
No convergence yet (steps count: 2400). Gelman-Rubin's R: 1.1161. Trying with the next bulk.
Convergence has been reached with 2600 steps. Gelman-Rubin's R: 1.0815. (2600 final count of samples).Again, as the proposal kernel has lower and upper bounds, then we are guaranteed that all proposed states are within the support of the parameter space.
Other tools
fmcmc is just one way to work with Markov Chain Monte Carlo. Besides stan and WinBUGS, there are other ways to do MCMC in R: mcmc, HybridMC, adaptMCMC, and elhmc among others (take a look at the CRAN Task View on Bayesian Inference.)
Contributing to fmcmc
We welcome contributions to fmcmc. Whether reporting a bug, starting a discussion by asking a question, or proposing/requesting a new feature, please go by creating a new issue here so that we can talk about it.
Please note that the ‘fmcmc’ project is released with a Contributor Code of Conduct. By contributing to this project, you agree to abide by its terms.